

Homework Assignment 5
This homework will make you more familiar with the Hadoop File System (HDFS) and the Hadoop mapreduce framework. You will be provided a disk image with everything pre-installed so hopefully the setup-phase for this homework will go smooth.
If you have one hour to spare I suggest that you watch this lecture from UC Berkeley. It will give you a great overview of what mapreduce is and what it is good at.
Overview
In this homework you will “do big data” on some weather data from the 18th century. The data will be given as many relatively small files (one for each year) so it will be easy for the tech-savvy ones to write a small program that will do what we ask of in Python (perhaps a nice way to double check your results before you hand them in ;). But since that is not very “big data” we will instead use Hadoop mapreduce.
The input data will be one .csv-file for each year in the period 1763 to 1799. Each of these files contains one row per measurement. To make things a little tricky there were only one weather station recording data in 1763 and at least two weather stations in 1799. Furthermore there are at least two measurements each day, one for the maximum temperature (TMAX) and one for the minimum temperature (TMIN), and sometimes one for the precipitation (PRCP).
The content of 1789.csv looks similar to this:
ITE00100554,17890101,TMAX,-63,,,E,
ITE00100554,17890101,TMIN,-90,,,E,
GM000010962,17890101,PRCP,4,,,E,
EZE00100082,17890101,TMAX,-103,,,E,
EZE00100082,17890101,TMIN,-184,,,E,
ITE00100554,17890102,TMAX,-16,,,E,
ITE00100554,17890102,TMIN,-66,,,E,
GM000010962,17890102,PRCP,15,,,E,
EZE00100082,17890102,TMAX,-98,,,E,
EZE00100082,17890102,TMIN,-170,,,E,
- Desciption of the columns:
- The weather station id
- the date in format yyyymmdd
- type of measurement (for this homework we care about the maximum temperature TMAX)
- temperature in tens of degrees (e.g. -90 = -9.0 deg. C., -184 = -18.4 deg. C.)
The Goal
The goal of this assignment is to create a sorted list for the most common temperatures (where the temperature is rounded to the nearest integer) in the period 1763 to 1799. The list should be sorted from the least common temperature to the most common temperature. The list should also state how many times each temperature occurred.
You solve this very important problem in two steps - task 1 and task 2.
Outline
The outline of the homework is as follows:
- Download and install the virtual disk image (homework5.ova)
- Intro to Hadoop File System (i.e. how to add/remove directories(s) and upload/download file(s))
- Intro to Hadoop Mapreduce (i.e. how to compile, run, and check the log-files of a mapreduce program)
- Task 1 - Count how many times each temperature occurs
- Task 2 - Sort the temperatures to see which is least/most common
Deadline and Deliverables
Deadline for this homework is May 12th. You will hand in your source code and the all result files.
Installing the necessary software
For this assignment everything is provided in the homework5.ova virtual disk image.
- Download the image
- homework5.ova
- Install it
- Start it
- Log in to
hduserwithcloudas password- You might have to switch user to from
Admintohduser - Works fine if you want to log in via
sshas well
- You might have to switch user to from
- Look around in the file system and make sure that you have:
weather- this will contain all you need for the homeworkweather/demo- a demo program for your inspiration/guideweather/task1- code skeleton for task 1weather/task2- code skeleton for task 2weather/data- contains all the input data you need
Get to know Hadoop File System (HDFS)
It’s now time to start playing around a little bit with HDFS! You will notice that it is almost exactly like navigating in a regular UNIX environment - just a zillion times slower…
First things first, you might have to start up HDFS and YARN:
Start HDFS
hduser@ubuntu1410adminuser:~$ cd hadoop hduser@ubuntu1410adminuser:~/hadoop$ sbin/start-dfs.shTest to see if HDFS is up and running:
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls / drwx------ - hduser supergroup 0 2015-03-30 11:19 /tmp drwxr-xr-x - hduser supergroup 0 2015-04-20 10:59 /userStart YARN
hduser@ubuntu1410adminuser:~/hadoop$ sbin/start-yarn.sh
Some basic HDFS commands:
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /
hduser@ubuntu1410adminuser:~$ hdfs dfs -mkdir /testing
hduser@ubuntu1410adminuser:~$ hdfs dfs -mkdir /testing2
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /testing
Create a text file sample.txt and add some content to it, then continue
hduser@ubuntu1410adminuser:~$ hdfs dfs -put sample.txt /testing/
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /testing/
hduser@ubuntu1410adminuser:~$ hdfs dfs -cat /testing/sample.txt
hduser@ubuntu1410adminuser:~$ hdfs dfs -get /testing/sample.txt downloadedSample.txt
hduser@ubuntu1410adminuser:~$ hdfs dfs -rm /testing/sample.txt
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /testing/
hduser@ubuntu1410adminuser:~$ hdfs dfs -rm -r /testing2
hduser@ubuntu1410adminuser:~$ hdfs dfs -ls /
A complete list of all the commands!
Get to know Mapreduce - our demo program
We will try to introduce mapreduce a bit through a demo, using the same weather data as you will use in Task 1 and Task 2. If you need to fresh up on what mapreduce is, I suggest that you take a look at the wikipedia page as well as the Hadoop MapReduce Tutorial.
Overview
The goal for this task is to take all the original weather data for the period 1763 to 1799 and run your own mapreduce program on it. The output of the mapreduce job should be a file for each weather station. Within these files you should list the days and temperatures that this weather station recorded. An overview can be seen below:
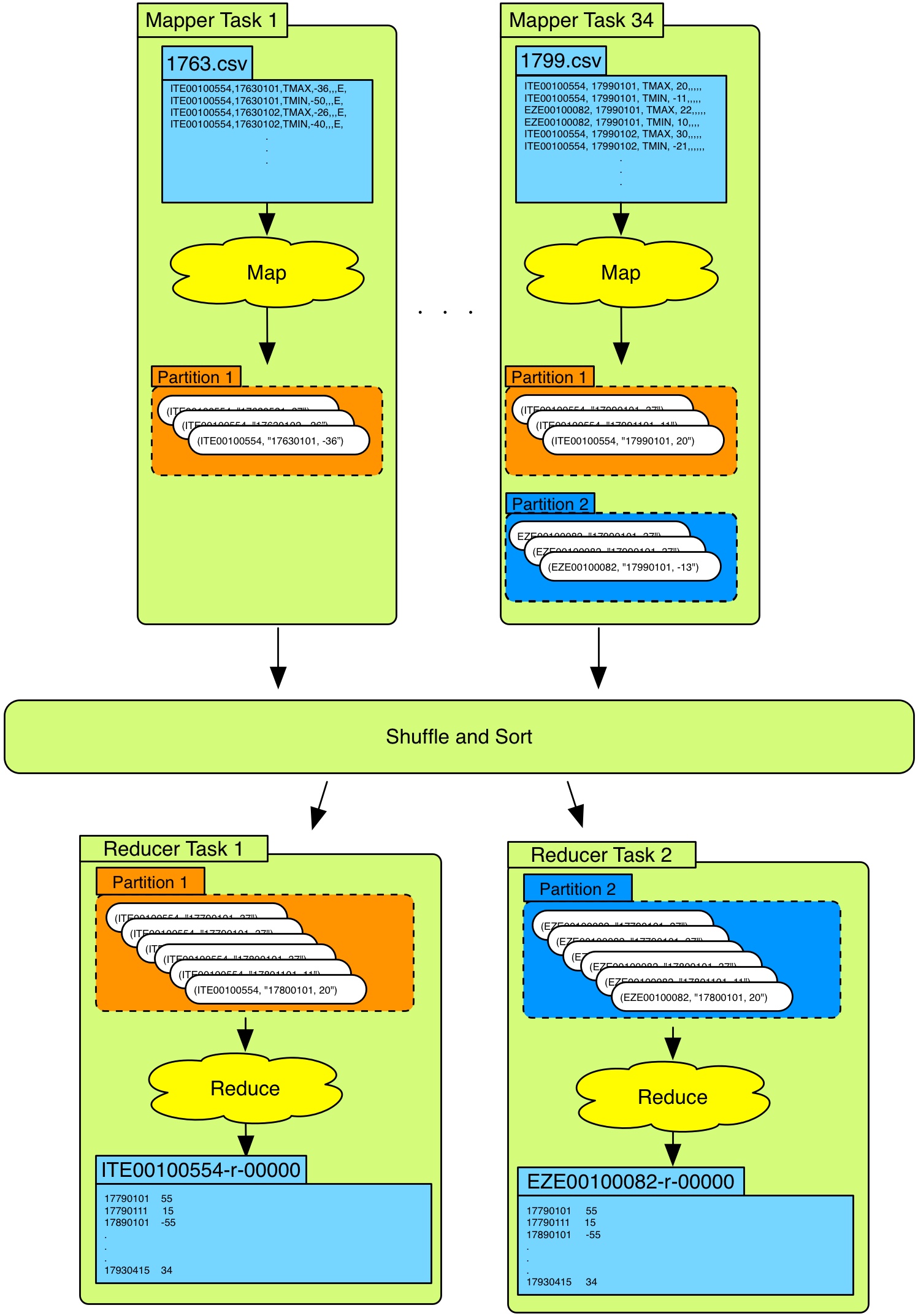
WeatherJob.java
This is the Main-file for the mapreduce program. In this you specify which mapper and reducer you will be using. You will also specify the input and output format for the mapper and reducer.
You will not have to modify any of the WeatherJob.java-files that we’ve given you!
Documentation for the mapreduce Job class.
WeatherMapper.java
- Input
- (key, value) = (
17xy.csv,row)17xy.csvis the input data filetextwill be the text-data within these.csvfiles- The
mapperwill be fed this text data row-by-row
- The input file might contain multiple weather stations
- The temperature is given in tens of degrees
- e.g. -123 = -12.3 degrees Celsius
- We only care about the maximum temperature for each day (TMAX)
- (key, value) = (
Output
- (key, value) = (weather-station-id, “date,temp”)
- e.g.
(ITE00100554, "17630101,-36") - “date,temp” should be submitted as one string
- Note that
keyandvalueis of typeText! Documentation for Text
Please take a moment to study the mapper-code!
String[] fields = value.toString().split(","); // reads and splits the input value (i.e. the row) Text v = new Text(date + "," + temp);` // creates a new Text-object with "date,temp" context.write(stationId, v); // writes the output of the mapper-task with key=stationId, value=v
Documentation for the mapreduce Mapper class
WeatherReducer.java
The specification of the reducer is as follows:
- Input
- (key, value) = (weather-station-id, “date,temp”)
- This is the output from the mapper
Output
- One output file per key (i.e. one output file per weather station)
- e.g.
ITE00100554-r-00000, orEZE00100082-r-00000 In these files you should list:
- the dates for when this temperature occurred
- the temperature
For the output file
ITE00100554-r-00000this would be:17860108 -3.1
17860107 -3.1
17860102 5.0
17860101 7.3
To write to an output file you can use the following method:
mos.write(k, v, key.toString() );where
k,v, andkey.toString()might be:k= “17860101”,v= “7.3”,key.toString()= “ITE00100554”kandvis of typeText- Documentation for Text
Please take a moment to study the reducer-code!
Iterator<Text> it = values.iterator(); // generate an iterator for the list of input-values String[] value = it.next().toString().split(","); // iterate to the next key-value pair and read the value mos.write(k, v, key.toString()); // write the key-value pair to a specified output-file
Documentation for the mapreduce Reducer Class
Compile and run the program
Follow this guide to compile and run the mapreduce demo:
- Make sure that
HDFSandYARNare up and running, otherwise start them Upload some new input data (
1779.csvand1780.csv):hduser@ubuntu1410adminuser:~$ cd weather/data hduser@ubuntu1410adminuser:~weather/data$ hdfs dfs -put 1779.csv /weather/input hduser@ubuntu1410adminuser:~weather/data$ hdfs dfs -put 1780.csv /weather/input hduser@ubuntu1410adminuser:~weather/data$ hdfs dfs -ls /weather/input/Compile the
mapreduce-program (make sure you’re in the correct directory)hduser@ubuntu1410adminuser:~weather/data$ cd ../demo hduser@ubuntu1410adminuser:~/weather/demo$ hadoop com.sun.tools.javac.Main *.javaTurn it into a runnable
.jar-file (namedwmr.jar):hduser@ubuntu1410adminuser:~/weather/demo$ jar cf wmr.jar *.classRun it!
- For this demo we have:
- jar.file =
wmr.jar - Main-method =
WeatherJob - Input path (in HDFS) =
/weather/input - Output path (in HDFS) =
/weather/result Note that the output path cannot be an existing directory!
hduser@ubuntu1410adminuser:~/weather/demo$ hadoop jar wmr.jar WeatherJob /weather/input /weather/result
Look at what it prints:
It should print something like this:
15/04/27 19:32:06 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/04/27 19:32:07 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 15/04/27 19:32:07 INFO input.FileInputFormat: Total input paths to process : 37 15/04/27 19:32:07 INFO mapreduce.JobSubmitter: number of splits:37 15/04/27 19:32:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1430155904361_0001 15/04/27 19:32:08 INFO impl.YarnClientImpl: Submitted application application_1430155904361_0001 15/04/27 19:32:08 INFO mapreduce.Job: The url to track the job: http://ubuntu1410adminuser:8088/proxy/application_1430155904361_0001/ 15/04/27 19:32:08 INFO mapreduce.Job: Running job: job_1430155904361_0001 15/04/27 19:32:21 INFO mapreduce.Job: Job job_1430155904361_0001 running in uber mode : false 15/04/27 19:32:21 INFO mapreduce.Job: map 0% reduce 0% 15/04/27 19:32:53 INFO mapreduce.Job: map 5% reduce 0% 15/04/27 19:32:54 INFO mapreduce.Job: map 16% reduce 0%Open up the web browser in the virtual machine and enter the
urlit gave you.- In this example the
urlwas: - http://ubuntu1410adminuser:8088/proxy/application14301559043610001/
- In this example the
You can also view the log-files in the file browser:
In this example it will be located in:
~/hadoop/logs/userlogs/application_1430155904361_0001/
Download and view the results:
hduser@ubuntu1410adminuser:~/weather/demo$ hdfs dfs -get /weather/result hduser@ubuntu1410adminuser:~/weather/demo$ ls /result- Now you should be able see all the output files from the mapreduce demo!
Task 1
The goal for this task is to take all the original weather data for the period 1763 to 1799 and run your own mapreduce program on it. The output of the mapreduce job should be a file for each degree of temperature that was present within this period. Within these files you should list the days (and for which weather station) this temperature was recorded. Furthermore, at the end of each file there should be a summation of the total number of times that this temperature occurred. An overview can be seen below:
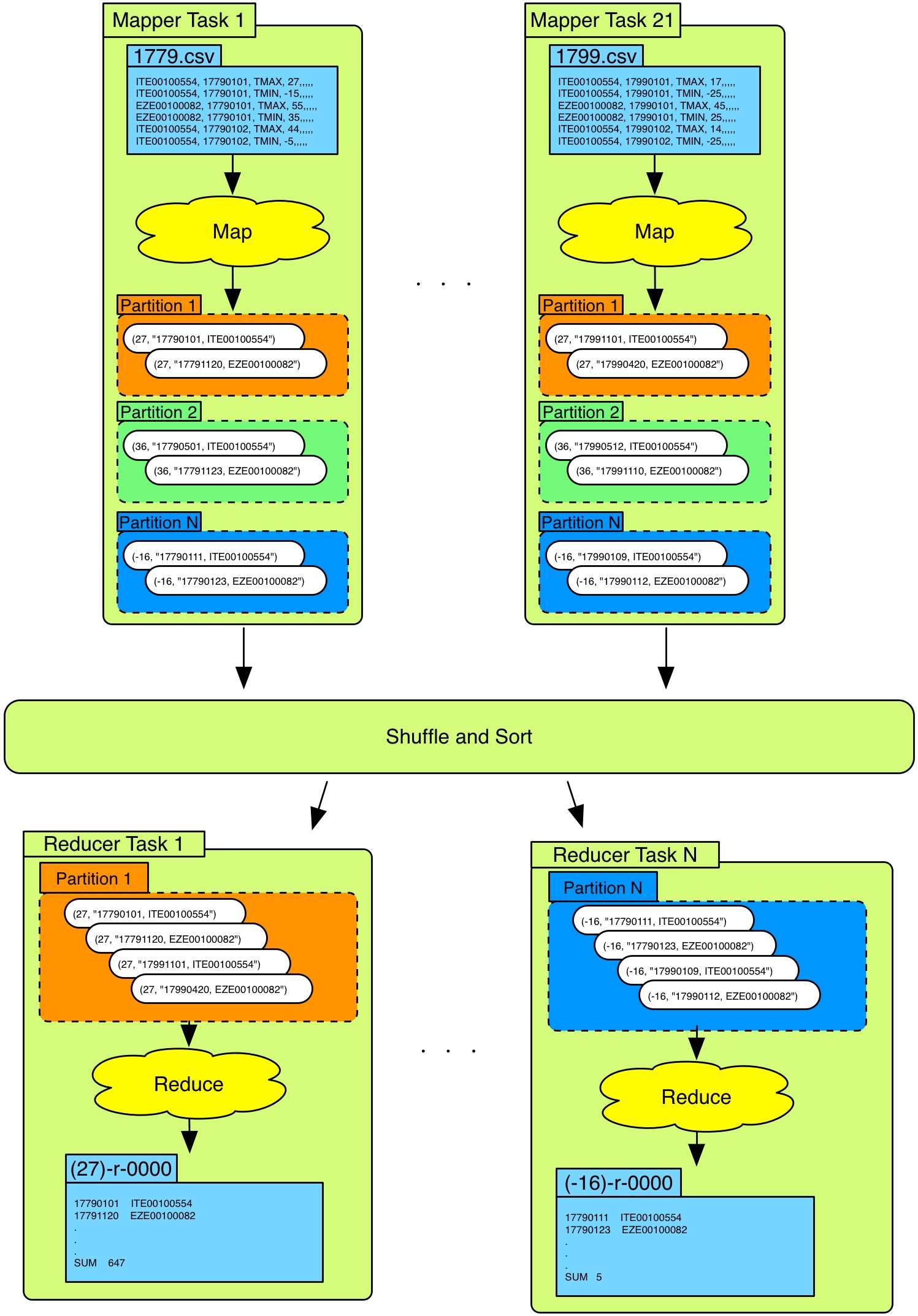
Mapper - specification
The specification of the mapper is as follows:
- Input
- (key, value) = (
17xy.csv,row)17xy.csvis the input data filetextwill be the text-data within these.csvfiles- The
mapperwill be fed this text data row-by-row
- The input file might contain multiple weather stations
- The temperature is given in tens of degrees
- e.g. -123 = -12.3 degrees Celsius
- We only care about the maximum temperature for each day (TMAX)
- (key, value) = (
- Output
- (key, value) = (temp, “date,weather-station-id”)
- temp should be in degrees Celcius and rounded to the nearest integer
- e.g. -123 => -12.3 => -12, 247 => 24.7 => 25
- “date, weather-station-id” should be submitted as one string
- Note that
keyandvaluehave to be of typeText! Documentation for Text
Reducer - specification
The specification of the reducer is as follows:
- Input
- (key, value) = (temp, “date,weather-station-id”)
- This is the output from the mapper
Output
- One output file per key (i.e. one output file per temperature)
- e.g.
(27)-r-00000, or(-16)-r-00000 In these files you should list:
- the dates for when this temperature occurred
- with which weather station that recorded it
- a summation of the total number of occurrences
For the output file
(-16)-r-00000this would be:17840104 EZE00100082
17881228 EZE00100082
17881218 EZE00100082
17890104 EZE00100082
17760120 EZE00100082
SUM 5
To write to an output file you can use the following method:
mos.write(k, v, "(" + key.toString() + ")");- where
k,v, andkey.toString()might be: k= “17840104”,v= “EZE00100082”,key.toString()= “-16”- or,
k= “SUM”,v= 5,key.toString() = “-16” kandvis of typeText- Documentation for Text
How to run it?
Example of how you can compile and run the program:
- Make sure that
HDFSandYARNare up and running, otherwise start them Compile the
mapreduce-program (make sure you’re in the correct directory)hduser@ubuntu1410adminuser:~/weather/task1$ hadoop com.sun.tools.javac.Main *.javaTurn it into a runnable
.jar-file (namedtask1.jar):hduser@ubuntu1410adminuser:~/weather/task1$ jar cf task1.jar *.classRun it!
- For this demo we have:
- jar.file =
task1.jar - Main-method =
WeatherJob - Input path (in HDFS) =
/weather/input - Output path (in HDFS) =
/weather/task1-output Note that the output path cannot be an existing directory!
hduser@ubuntu1410adminuser:~/weather/task1$ hadoop jar task1.jar WeatherJob /weather/input /weather/task1-output
Task 2
The goal for this task it to take the output from the previous task and use as input for this task. The output of this task should be just one file. In this file you should have a sorted list showing which temperature was most common and how many times this temperature occurred. An overview can be seen below:
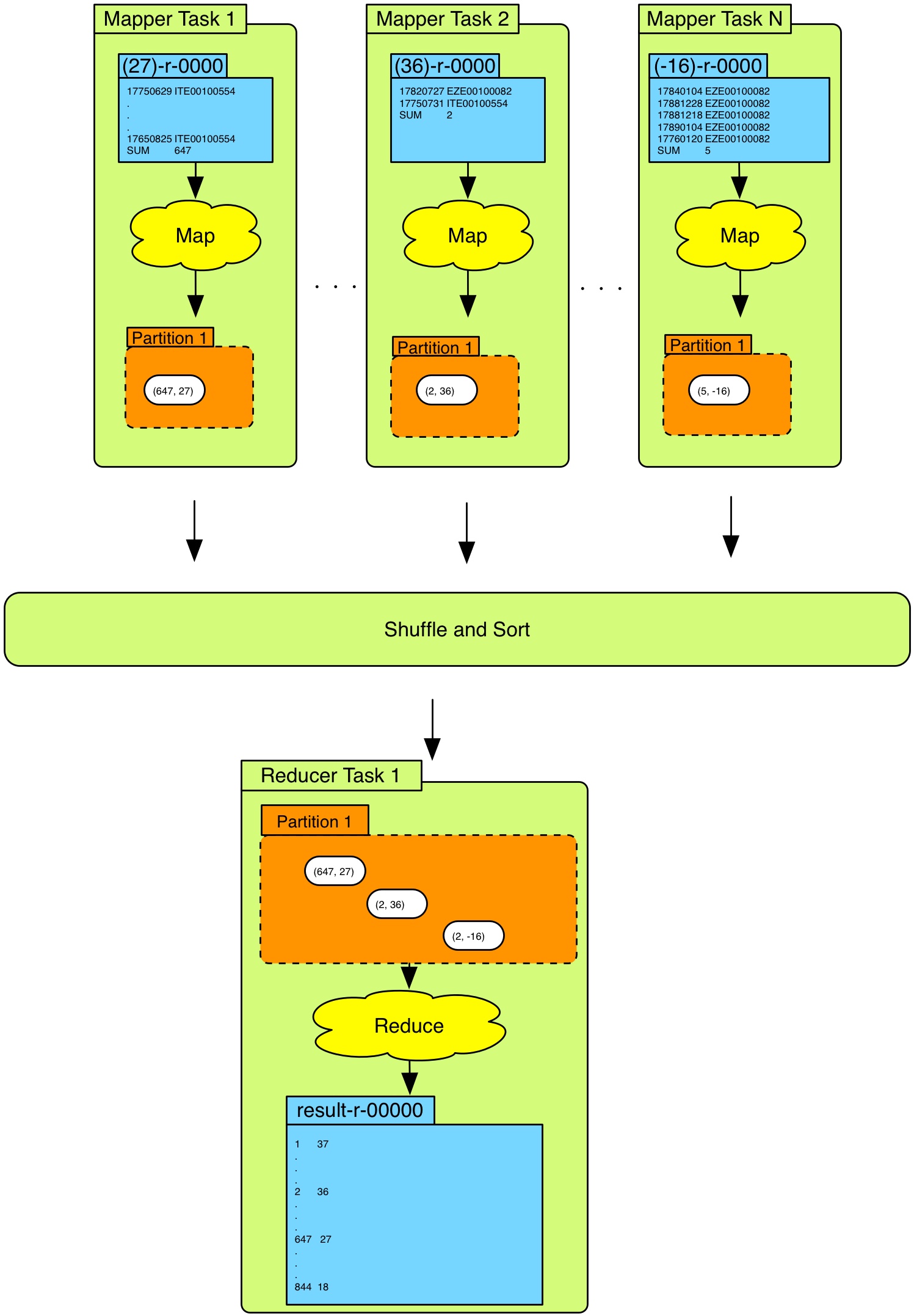
Mapper - specification
The specification of the mapper is as follows:
Input
- (key, value) = (
(temp)-r-00000,row)(temp)-r-00000is the input data file produced in task 1textwill be the text-data within these files- The
mapperwill be fed this text data row-by-row
To extract the filename of the input file you can use:
String filename = ((FileSplit) context.getInputSplit()).getPath().getName();
- (key, value) = (
- Output
- (key, value) = (numOccurrences, “temp”)
- If you did task 1 properly it should be easy to retrieve numOccurrences
keyis of classIntWritable- Documentation for IntWritablevalueis of typeText- Documentation for Text
Reducer - specification
The specification of the reducer is as follows:
- Input
- (key, value) = (numOccurrences, “temp”)
- This is the output from the mapper
Output
- One output file which contains a sorted list of the most common temperature
- Least common temperature first
- Should also show how many times each temperature occurred
Example:
1 37.0 2 36.0 2 -21.0 3 35.0 . . . 836 24.0 842 23.0 844 18.0When you only want to write to one output file you can use:
context.write(k, v);- Where
kandvmight be k= 3,v= “35”- Note that
kandvhave to be of typeText! Documentation for Text To convert an
IntWritabletoTextyou can use:Text k = new Text(key.toString());
How to run it?
Example of how you can compile and run the program:
- Make sure that
HDFSandYARNare up and running, otherwise start them Compile the
mapreduce-program (make sure you’re in the correct directory)hduser@ubuntu1410adminuser:~/weather/task2$ hadoop com.sun.tools.javac.Main *.javaTurn it into a runnable
.jar-file (namedtask2.jar):hduser@ubuntu1410adminuser:~/weather/task2$ jar cf task2.jar *.classRun it!
- For this demo we have:
- jar.file =
task2.jar - Main-method =
WeatherJob - Input path (in HDFS) =
/weather/task1-output - Output path (in HDFS) =
/weather/task2-output Note that the output path cannot be an existing directory!
hduser@ubuntu1410adminuser:~/weather/task2$ hadoop jar task2.jar WeatherJob /weather/task1-output /weather/task2-output